- Eine robuste und preiswerte Oracle HA-Lösung
- Für alle Datenbank Editionen anwendbar
- Eine mögliche Alternative zum RAC und zum Data Guard
- Inklusive eines universellen Cluster-Filesystems
Hinweis: Es ist ein neuer Artikel veröffentlicht, der den Aufbau einer Single Instance Failover Cluster mit der Grid Infrastructure 19c zum Thema hat:
//frankgerasch.de/2019/05/oracle-se2-im-cluster-es-geht-auch-ohne-rac/
Einführung
Die Nutzung der Oracle Clusterware zum Aufbau eines Single Instance Failover Clusters ist schon seit Jahren ein geeignetes Mittel zur Absicherung eines Datenbankservices gegen Serverausfall. Da die Oracle Standard Edition bereits die Nutzung der Oracle Real Application Cluster (RAC) Option beinhaltet, wurde in der Praxis jedoch vorzugsweise eher ein RAC mit zwei Knoten für diesen Zweck implementiert. Selbst dann, wenn eine Skalierung der Last über beide Knoten hinweg nicht erforderlich gewesen wäre, da z.B. ein einzelner Knoten die Anwendungslast alleine hätte stemmen können.(öffnet in neuem Tab)
Standard Edition Two – Ein neues Argument
Aufgrund der lizenzrechtlichen Einschränkung der neuen Datenbank Standard Edition Two (SE2) , hinsichtlich der maximalen Anzahl der CPU Sockel in einem 2-Knoten RAC (1 CPU Sockel pro Knoten), erlebt das Modell „Single Instance Failover Cluster“ gerade wieder eine Renaissance. Aus Mangel an verfügbaren Servern mit lediglich nur einem CPU Sockel auf dem Markt, lässt sich ein 2-Knoten RAC mit der SE2 wohl kaum realisieren. Die RAC One Node Option, die von der Funktionsweise am ehesten vergleichbar mit einem Single Instance Failover Cluster ist, benötigt die Enterprise Edition der Datenbank und ist zusätzlich mit Extrakosten für die Lizenzierung der Option verbunden. Alle drei HA-Lösungen haben eine Gemeinsamkeit. RAC, RAC One Node und Single Instance Failover Cluster basieren auf der Oracle Clusterware, die genauso wie das Automatic Storage Management (ASM), Bestandteil der Grid Infrastruktur ist und den Kern der jeweiligen Lösung bildet.
Inhaltsbeschreibung
Ich möchte in diesem Artikel zunächst kurz die Architektur und Funktionsweise eines „Single Instance Cold Failover Clusters“ sowie eines „Extended Distance Clusters“ erläutern. Anschließend werde ich eine Kombination beider Technologien beschreiben, die für eine Vielzahl von Anwendern interessant sein dürfte und die ich mit „Single Instance Failover Cluster (Extended Distance)“ in meinem Post betitelt habe.
Des Weiteren gehe ich auf ein interessantes Betriebskonzept der Verteilung der Instanzen nach Prioritäten ein, bei dem die Instanzen hinsichtlich ihrer Wichtigkeit für den Geschäftsbetrieb auf beide Clusterknoten verteilt werden. Im Fehlerfall werden die Datenbanken mit der höheren Priorität gegenüber den Datenbanken mit niedriger Priorität bevorzugt. Als Hilfestellung zu einer möglichen Umsetzung, habe ich eine Kurzanleitung zur Einrichtung einer solchen Konstellation in der aktuellen Version der Datenbank und Grid Infrastruktur bereitgestellt. Neben der Steuerung der neu angelegten Datenbank-Intanz Cluster Ressourcen, wird auch das Anlegen von Services mit dem zu nutzenden Oracle Package DBMS_SERVICE erläutert. Zu guter Letzt werde ich die Vor- und Nachteile eines „Single Instance Failover Clusters (Extended Distance)“, inbesondere gegenüber RAC und RAC Node, beleuchten. Das grundlegenden Verständnis für den Betrieb und den Aufbau der Grid Infrastructure und des Basismodell des Real Application Cluster wird für diesen Bericht vorausgesetzt.
1. Single Instance Cold Failover Cluster
Ein Oracle Single Instance Cold Failover Cluster ist grundsätzlich wie eine RAC aufgebaut, welches die Oracle Clusterware zur Steuerung der Cluster Ressourcen verwendet. Die abzusichernde Datenbank-Instanz wird jedoch als „Single Instance“ nur auf einem der Knoten und nicht als „RAC Instance“ auf beiden Knoten parallel betrieben. Bei Ausfall eines Knotens muss die Instanz auf dem zweiten Knoten zunächst gestartet werden, bevor die Datenbank-Anwendungen weiterarbeiten können. Im Gegensatz zu einem RAC ist daher mit einem kurzen Ausfall des Datenbankservices zu rechnen.

Die Basisfunkionalität unterscheidet sich nicht von dem eines klassischen RAC. Die Anwendungs-Clients verbinden sich über das Public Netzwerk mit Hilfe des Single Client Access Namen (SCAN) mit der Datenbank. Für die Clients besteht nicht die Notwendigkeit wissen zu müssen, auf welchem Knoten die Instanz nun gerade läuft. Die Clusterkommunikation erfolgt über ein privates Netzwerk zwischen den Knoten (Interconnect). Und die Clusterintegrität wird über eine Voting Disk (Quorum) zur Vermeidung eines Split Brain sichergestellt.
Datenbank-Instanz als Cluster Ressource & Action-Script
Im Unterschied zum RAC oder RAC One Node wird die Datenbank in einem Failover Cluster nicht als „Datenbank Ressource“, sondern die Datenbank-Instanz als „Cluster Ressource“ angelegt. Dies impliziert, dass zur Steuerung der Datenbankinstanz nicht SRVCTL, sondern CRSCTL als Werkzeug genutzt werden muss. Damit sich die Cluster Ressource auch von der Clusterware steuern lässt, muss diese wissen wie dies passieren soll. Die Clusterware muss in der Lage sein die Ressource zu stoppen, zu starten, den Status zu ermitteln und im Fehlerfall zu bereinigen. Für diesen Zweck muss auf ein Action-Script referenziert werden, welche diese vier Funktionen enthält. Oracle stellt übrigens für die Steuerung anderer Anwendungen aus dem Hause Oracle sogenannte Oracle Grid Infrastructure Agents (XAG) bereit, die diese Funktion ebefalls übernehmen, wenn man eine solche Anwendungen mit der Clusterware absichern und steuern möchte.
2. Extended Distance (Streched) Cluster
Für diejenigen, die sich nicht nur gegen den Ausfall des Datenbankservers schützen wollen, sondern die Verfügbarkeit ihrer Datenbanken beim Ausfall einer ganzen Site sicherstellen müssen, ist das Architekturmodell des Extended Distance Clusters sehr attraktiv.
 |
| Extended Distance (Streched) Cluster |
Der für eine Cluster-Architektur typische Shared Storage wird dabei über zwei Standorte hinweg „auseinandergezogen“ (streched) und an jedem der beiden Standorte ein Datenbankserver betrieben. Standorte könnten z.B. zwei Rechenzentren auf dem Firmengelände sein. In dem Szenario kann der Ausfall eines ganzen Rechenzentrums, durch z.B. eine Unterbrechnung der Stromversorgung, der Verfügbarkeit des Datenbankservices (fast) nichts anhaben. Die Datenbankdateien befinden sich gespiegelt auf dem Storage Array im verbliebenden zweiten RZ und die Datenbank-Instanz wird von der Clusterware auf dem Datenbankserver im zweiten RZ hochgefahren.
ASM Mirroring
Die Spiegelung/Synchronisierung zwischen den beiden Storrage Arrays wird durch das Oracle ASM bewerkstelligt. Da die Verzögerung der Schreibzugriffe auf das entfernte Storage Array mit der Distanz zunimmt und ebenso von der technischen Anbindung abhängig ist, sind der Entferung beider Knoten folglich Grenzen gesetzt. Bis zu 10 Km sollten in der Praxis damit aber überbrückbar sein. Damit bei IO intensiven und performancekritischen Anwendungen die IO-Spiegelung nicht zu einem Performancengpass führt, sollten die beiden Storage Arrays mit Fibre Channel angebunden werden.
Voting Disks
Im Unterschied zu einem normalen Cluster sollten bei einem Extended Distance Cluster immer 3 Voting Disks an unterschiedlichen Standorten bereitgestellt werden. Die ersten beiden Voting Disks werden überlicherweise auf den Storrage Arrays an den beiden Datenbankserver-Standorten gelegt. Die dritte Voting Disk sollte an einem dritten Standort abgelegt werden und kann via SAN oder auch NFS angebunden werden. Durch diese Verteilung wird sichergestellt, dass selbst bei einem Ausfall eines Standortes der überlebende Server mindestens zwei der Voting Disks erreicht und somit seine Mitgliedschaft zum Cluster bestätigen kann. Würde nur eine Voting Disks seitens des überlebenden Servers sichtbar sein, dann kann der überlebende Server keine zuverlässige Aussage über seinen Mitgliedsstatus treffen und wird zum Schutz der Datenbankintegrität von der Clusterware herunterfahren (Node Eviction).
Lizenzierung
Ein Extended Distance Cluster setzt immer die volle Lizenzierung der Datenbanksoftware auf beiden Oracle Knoten voraus, selbst wenn im Normalbetrieb keine Datenbank-Instanzen auf dem zweiten Knoten laufen würden. Man kann sich also nicht auf die 10-Tage Failover-Regelung von Oracle berufen, bei dem nur der aktive Knoten zu lizenzieren ist, wenn nicht mehr als 10 Tage in der Summe mit der Datenbank-Instanz auf den Failoverknoten geschwenkt wird. Begründet wird dies durch den Einsatz der gespiegelten/synchronisierten Storage Arrays, bei dem die Anwendung der 10-Tage Failover-Regelung laut Lizenzbedingungen nicht gültig ist. Welche Technologie für die Spiegelung/Synchronisierung zum Einsatz kommt (hier ASM Mirroring), ist nicht maßgeblich.
Der Einsatz der Clusterware und ASM/ACFS fällt unter die „Special-Use“-Lizenzierung und ist im Übrigen kostenlos und kann für die Failover-Absicherung jeglicher Anwendungen genutzt werden. Support für die Grid Infrastructure (Clusterware und ASM/ACFS) gibt allerdings nur, wenn ein Oracle Produkt auf dem Server läuft. Dies beinhaltet auch Oracle Linux und Solaris, solange Support für beide Betriebssysteme existiert. Bei der Nutzung von einigen ACFS-Zusatzfeatures, z.B. ACFS Snapshot, gibt es allerdings Lizenzeinschränkungen. Hier sollte das Lizenzinformationsdokument von Oracle beachtet werden.
„Oracle Clusterware provides cluster membership and high availability monitoring and failover. Oracle Clusterware may be used to protect any application (restarting or failing over the application in the event of a failure) on any server, free of charge. Oracle will provide support for Clusterware only if the server is running an Oracle product, which may include Oracle Linux or Oracle Solaris, that is also under Oracle support.“
„Oracle will provide support services for Oracle ACFS only if the server it operates on also operates an Oracle product, which may include Oracle Linux or Oracle Solaris, which is under an Oracle support contract“
Referenz: //docs.oracle.com/database/121/DBLIC/editions.htm#DBLIC119
3. Single Instance and Failover Cluster (Extended Distance)
Beide Architekturen, Single Instance Failover Cluster und Extended Distance Cluster, lassen sich sehr gut kombinieren, um eine robuste und kostengünstige Absicherung eines Datenbankstandortes zu erreichen. Da in einem Extended Distance Cluster immer beide Knoten zu lizensieren sind, macht es aus wirtschaftlicher Sicht Sinn, zumindest beim Betrieb von mehreren Datenbanken, die jeweiligen Instanzen auch auf beide Knoten zu verteilen.
Betriebskonzept: Verteilung der Instanzen nach Priorität
Folgende Clusterkonfiguration ist insbesondere geeignet, wenn man mehrer Datenbank-Instanzen unterschiedlicher Priorität in dem Cluster betreibt, die einzelnen Knoten jedoch nicht so gut ausgestattet sind, dass diese im Fehlerfall Ressourcen für alle Instanzen zur verfügung stellen könnten.
 |
| Beispiel Regelbetrieb – Single Instance Failover Cluster (Extended Distance) |
Man könnte dann z.B. die Instanzen der kritischen produktiven Datenbanken auf dem ersten Knoten laufen lassen und die Instanzen der weniger kritischen Test-Datenbanken auf dem zweiten Knoten. Beim Ausfall des kritischen Servers würden dann die Instanzen der produktiven Datenbanken auf den zweiten Server schwenken und zuvor automatisch die weniger kritischen Instanzen der Test-Datenbanken heruntergefahren werden. Der Betrieb der kritischen Datenbankservices wird somit auf Kosten der weniger kritischen Datenbanken sichergestellt. Man erreicht ein solches Verhalten, indem man zwei Server Pools mit unterschiedlicher Priorität anlegt und die Datenbank-Instanzen dann dem der Priorität entsprechenden Server Pool zuweist.
Partitionierung des Clusters durch Server Pools
Das Server Pool Konzept funktioniert so, dass jeder der beiden Knoten in dem Cluster einem Server Pool mit unterschiedlicher Priorität zugewiesen wird. Jeder Server Pool hat in dem Fall also nur einen Knoten als Mitglied. Fällt der Knoten, der Mitglied des Server Pools mit höhrerer Priorität ist, aus, so übernimmt der höher priorisierte Server Pool den zweiten Knoten. Da ein Knoten immer nur Mitglied eines Server Pools sein kann, hat dies zur Folge, dass der niedrig priorisierte Server Pool, und folglich auch seine Mitglieder, heruntergefahren wird. Die Datenbanken, die Mitgied des Server Pools mit höhere Priorität sind, werden auf dem zweiten Knoten gestartet.
Verhalten bei einem Knotenausfall
Nachfolgend möchte ich einmal aufzeigen wie sich der in diesem Betriebskonzept beschriebene Cluster beim einem Ausfall eines Datenbankservers im Detail verhält.
1. Host/Site A fällt aus. Die weniger kritischen Datenbanken (hier Test) werden auf dem Host B heruntergefahren, um Ressourcen für den Start der kritischen Datenbanken (hier Prod) frei zu machen.
 |
|||||
| Test-Datenbanken auf Host B werden von der Clusterware heruntergefahren |
| Test-Datenbanken sind heruntergefahren |
2. Nachdem der überlebende Host B frei ist, werden die kritischen Datenbanken (Prod) auf dem Host B gestartet und stehen wieder zur Verfügung.
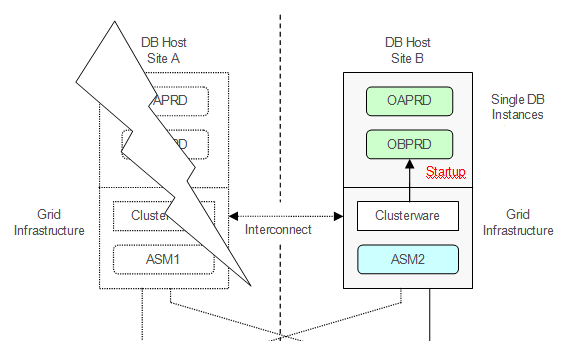 |
| Produktions-Datenbanken werden hochgefahren |
3. Sobald Host/Site A wieder verfügbar ist, werden die Test-Datenbanken wieder auf dem jetzt freien Host A gestartet und stehen ebenfalls wieder zur Verfügung.
 |
| Host/Site A steht wieder zur Verfügung |
 |
| Test-Datenbanken werden wieder hochgefahren |
Kurzanleitung zur Einrichtung eines Single Instance Failover Cluster (Extended Cluster)
Nachfolgend möchte ich eine Kurzanleitung zur Verfügung stellen, um einen Single Instance Failover Cluster (Extended Distance) zu erstellen. Schwerpunktmäßig möchte ich auf die notwendigen Schritte eingehen, die sich von der Installation eines normalen RAC unterscheiden und daher der besonderen Beachtung bedürfen.
- Installation und Einrichtung der Clusterhardware und Netze analog eines normalen RAC.
- Installation der Oracle Grid Infrastructure Software wie gewohnt auf beiden Knoten.
- Vorbereitung des Shared Storage: ASM Diskgroups und ACSF Filesystem(e) zur Aufnahme der Datenbankdateien erstellen. Darauf achten, dass die ASM Disks Groups mit Redundancy „Normal“ (2-way Mirror) angelegt werden und diese immer aus zwei Failure Groups bestehen. Die Disks der ersten Failure Group müssen alle von dem Storage Array des einen Standortes und die Disks der zweiten Failure Group von dem Storage Array des zweiten Standortes kommen. Dies ist notwendig, damit der Ausfall des Storage Arrays eines Standortes nicht die Verfügbarbeit der ASM Disk Group negativ beinflusst.
- Installation der Datenbanksoftware auf jedem Knoten (lokaler Storage) als „Single Instance Database Installation“. Darauf achten, dass diese nicht als „Oracle Real Application Cluster Database Installation“ oder als „Oracle RAC One Node Database Installation“ installiert wird.
- Datenbank nach eigenen Vorgaben auf dem ersten Knoten als Single Instance erstellen. Als Speicherort für die Datenbankdateien die zuvor angelegte ASM Disk Group oder ggf. das zuvor erstellte ACFS Filesystem angeben.
- Da die nun erstellte Datenbank sich vermutlich bei der Clusterware als „Oracle Restart“-Datenbank registriert hat, muss diese aus der Clusterware wieder wie folgt entfernt werden.
srvctl remove database -d <database name> - Das Oracle Spfile der zurvor angelegten Instanz wurde vom Oracle Installer unter $ORACLE_HOME/dbs/ auf dem lokalen Storage des ersten Knoten angelegt. Damit der Start der Instanz zukünftig von beiden Knoten aus möglich ist, muss das Spfile von beiden Knoten aus erreichbar sein. Aus diesem Grund muss das Spfile nun in eine ASM Disk Group oder das (Shared) ACFS Filesystem verlagert werden.
- Damit die Instanz auf jedem Knoten das Spfile einlesen kann, muss dieses von einem lokal verfügbaren Oracle Pfile referenziert werden. Dazu sollte auf jedem Knoten ein leeres Pfile angelegt werden ( $ORACLE_HOME/dbs/init<sid>.ora) und ein Zeile hinzugefügt werden die auf das verlagerte Spfile zeigt (SPFILE=’Pfad zum sfpile‘).
- Auf dem zweiten Knoten das notwendige Audit-Verzeichnis für die Instanz erstellen (siehe Instance Parameter audit_file_dest).
- Action-Script für die Datenbankinstanz auf dem lokalen Storage beider Knoten anlegen. (Beipielpfad: /u01/app/oracle/admin/<sid>/action_script/action.sh). Ein Beispiel für ein Action-Script aus meinem letzten Blog-Beitrag ist hier hinterlegt.
- Server Pools anlegen. Der Name eines Server Pools kann frei gewählt werden. Für den Fall, dass nach dem von mir obenen beschriebene Betriebskonzept „Verteilung der Instanzen nach Priorität“ umgesetzt werden soll, so müssen zuvor zwei Server Pools entsprechend angelegt werden. Wenn jedoch alle Hosts alle Cluster Ressourcen bei einem Ausfall eines Hosts übernehmen sollen (und können), so kann man auf das Anlegen von Server Pools verzichten. In dem Fall laufen dann alle Instanzen auf dem überlebenden Hosts und keine Instanzen werden heruntergefahren.a.) Server Pool für die Datenbanken mit geringer Priorität erstellen als (Grid Infrastructure Owner).
crsctl add srvpool lowpriority.sp -attr "IMPORTANCE=0,MIN_SIZE=1,MAX_SIZE=1,SERVER_NAMES=ora1srv ora2srv" crsctl status srvpool lowpriority.sp -f
b.) Server Pool für die Datenbanken mit höherer Priorität erstellen (Als Grid Infrastructure Owner)
crsctl add srvpool highpriority.sp -attr "IMPORTANCE=1,MIN_SIZE=1,MAX_SIZE=1,SERVER_NAMES=ora1srv ora2srv" crsctl status srvpool highpriority.sp -f
- Cluster Ressourcen für die Datenbank-Instanzen anlegen. Der Name der Cluster Ressource für eine Datenbank-Instanz (hier z.B. oatst.inst) kann frei gewählt werden, sollte aber nicht „ora.“ beginnen, da dieses Prefix für von Oracle verwaltete Ressourcen reserviert ist.a) Cluster Ressource für die Datenbank mit geringerer Priorität erstellen (Test DB)
crsctl add resource oatst.inst -type cluster_resource -attr "ACTION_SCRIPT=/u01/app/oracle/admin/oatst/action_script/action.sh, CHECK_INTERVAL=15, RESTART_ATTEMPTS=1, FAILURE_THRESHOLD=2, FAILURE_INTERVAL=60, UPTIME_THRESHOLD=1h, SERVER_POOLS=lowpriority.sp, PLACEMENT=favored, DESCRIPTION=Oracle Failover Instance, START_DEPENDENCIES='weak(type:ora.listener.type,global:type:ora.scan_listener.type)pullup(global:ora.acfs.acfsvol.acfs) hard(global:uniform:ora.acfs.acfsvol.acfs)' STOP_DEPENDENCIES='hard(global:intermediate:ora.acfs.acfsvol.acfs)'" crsctl status res oatst.inst -f
b) Cluster Ressource für die Datenbank höherer Priorität erstellen (Prod DB)
crsctl add resource oaprd.inst -type cluster_resource -attr "ACTION_SCRIPT=/u01/app/oracle/admin/oaprd/action_script/action.sh, CHECK_INTERVAL=15, RESTART_ATTEMPTS=1, FAILURE_THRESHOLD=2, SERVER_POOLS=highpriority.sp, PLACEMENT=favored, FAILURE_INTERVAL=60, UPTIME_THRESHOLD=1h, DESCRIPTION=Oracle Failover Instance, START_DEPENDENCIES='weak(type:ora.listener.type,global:type:ora.scan_listener.type)pullup(global:ora.acfs.acfsvol.acfs)hard(global:uniform:ora.acfs.acfsvol.acfs)' STOP_DEPENDENCIES='hard(global:intermediate:ora.acfs.acfsvol.acfs)' crsctl status res oaprd.inst -f
Referenz der Cluster Ressource Attribute:
//docs.oracle.com/database/121/CWADD/crsref.htm#CHDIHGHE //docs.oracle.com/database/121/CWADD/resatt.htm#CWADD91383
Steuern der angelegten Datenbank Cluster Ressource
Beipiel Starten der Datenbank:
crsctl start resource oatst.inst
Beispiel Stoppen der Datenbank:
crsctl stop resource oatst.inst
Verschieben der Datenbank auf den zweiten Host
(Nur möglich, wenn keine Gebrauch von Serverpools gemacht worden ist)
crsctl relocate resource odb.inst
Beispiel Deaktivierung Autotart der Datenbank:
crsctl modify resource oatst.inst –attr "ENABLED=0"
Verwaltung von Services mit DBMS_SERVICE
In einem Single Instance Failover Cluster können nicht, wie etwa bei einem RAC oder RAC One Node, die Datenbank Services mit SRVCTL angelegt und verwaltet werden. Stattdessen müssen die Services mit dem Oracle Package DBMS_SERVICE gemanaged werden, falls es erforderlich sein sollte Services nutzen zu müssen oder wollen.
Erstellen eines Services:
DBMS_SERVICE.CREATE_SERVICE ( service_name IN VARCHAR2, network_name IN VARCHAR2, parameter_array IN svc_parameter_array );
Beispiel:
SQL> exec dbms_service.CREATE_SERVICE(SERVICE_NAME=>'MyTestService', NETWORK_NAME=>'MyTestService');
Beipiel Start eines Services:
SQL> exec DBMS_SERVICE.START_SERVICE('MyTestService');
Anzeige der Services in der Datenbank:
set linesize 130 col name for a15 col network_name for a15 col creation_date for a14 col clb_goal for a14 SELECT name,network_name, creation_date, clb_goal FROM dba_services;
Referenz: //docs.oracle.com/database/121/ARPLS/d_serv.htm#ARPLS092
ASM Cluster Filesystem – ACFS
Dass mit Oracle ASM zur Verfügung stehende Clusterfilesystem ACFS ist nicht nur geeignet, um die Datenbankdateien aufzunehmen, sondern kann universell eingesetzt werden. Da das Filesystem auf jedem Knoten zur Verfügung steht, ist es auch wie geschaffen dafür, failoverfeste Dateissystemschnittstellen oder andere, von einer Anwendung benötigte Verzeichnisse und Dateien bereitzustellen.
Patching
Das Einspielen von Patches unterscheidet sich nicht von dem einer Single Instance Installation. Die Grid Infratructure- und Datenbanksoftware muss getrennt voneinander auf jedem Kmoten einzeln mit Patches versorgt werden. Ein RAC-Enabled Patching und „opatch auto“ ist hier nicht möglich.
Vor- und Nachteile eines Single Instance failover Cluster (Extended Distance)
Vorteile gegenüber eines RAC:
- Bei Enterprise Edition: Kostengünstiger, da keine Lizenz für die RAC Option notwendig ist
- Bei Standard Edition Two: 2 CPU Sockel statt 1 CPU Sockel pro Knoten möglich
- Kein breitbandiger Interconnect notwendig, da kein Cache Fusion genutzt wird
Vorteile gegenüber eines RAC One Node:
- Bei Enterprise Edition: Kostengünstiger, da keine Lizenz für die RAC One Node Option notwendig
- Für alle Editionen einsetzbar – nicht nur bei der Enterprise Edition
Nachteile gegenüber RAC & RAC One Node:
- Zur Steuerung der Instanz muss statt dem Server Control Utility (srvctl) das Clusterware Control Utility (crsctl) genutzt werden
- Failover-Integration in Enterprise Manager nicht vorhanden
- Kein RAC enabled Oracle Home
- Aufbau und Betrieb erfordert mehr KnowHow
Nachteile gegenüber RAC:
- Keine Skalierung der Last auf mehrere Knoten möglich. Kein Loadbalancing
- Failover der Instanz ist nicht unterbrechungsfrei. Kurzer Ausfall des Datenbankservices notwendig.
Nachteile gegenüber RAC One Node:
- Keine Online Database Instance Relocation möglich
Fazit
Eine Oracle Single Instance Failover Cluster (Extended Distance) ist für alle geeignet, die eine robuste und kostengünstige Möglichkeit suchen, um ihre Oracle Datenbanken im Rahmen eines Failover Clusters abzusichern und die auf eine kurze Nichtverfügbarkeit Ihrer Datenbankservice im Failoverfall oder beim Patchen tolerieren können.
Hi Frank,
ein sehr guter Artikel, im Grunde genau was wir bräuchten.
Mich interessiert noch, ob die vorgestellte Architektur auch von Oracle supportet wird bzw. wo die Grenzen liegen.
Ich könnte bspw. mir vorstellen, dass Oracle für das selbst definierte Action-Skript vermutlich keinen Support leisten wird.
Allerdings wäre eine generelle Aussage hinsichtlich Support für die Kombination von Single-Instance und Oracle Clusterware hilfreich.
Weiterhin existiert nun bereits die Clusterware in der Version 18. Gibt es hier eventuell Neuerungen hinsichtlich Unterstützung
eines Cold Failover Clusters für die Oracle Datenbank?
Unter Windows gibt es bekanntlich FailSafe. In unserer Umgebung ist Linux geplant, daher wäre eine „eingebaute“
Failover-Cluster-Unterstützung für die Oracle Datenbank in der Oracle Clusterware sehr vorteilhaft.
MfG,
Stefan
Hallo Stefan,
die Grid Infrastructure und die Single Instance Datenbank wird nach wie vor von Oracle supported. Für den Support der Clusterware ist es nicht relevant, ob eine Datenbank als RAC, RAC One Note oder Cluster Ressource eingebunden ist.
Hinsichtlich des Supports der Single Instance Datenbank ist es ebenfalls nicht relevant, durch was diese automatisch gestartet wird. Ja, es ist korrekt, dass Oracle für selbsdefinierte Action-Scripte für den Start- und Stopp der Single Instance keinen Support leistet. Gleiches gilt aber auch für selbstdefinierte Action-Scripte für andere Third-Party-Software, für die es keine von Oracle angebotene Action-Scripte gibt.
Mir sind keine Neuerungen hinsichtlich einer Cold Failover Funktionalität bei GI 18c bekannt. Ich plane übrigens den Single-Instance Failover Cluster mit der GI 18c zu testen. Falls es gegenüber 12c neue oder abweichende Erkenntnisse geben sollte, werde ich einen Blog-Beitrag dazu veröffentlichen.
Hi Frank,
ein sehr guter Artikel, im Grunde genau was wir bräuchten.
Mich interessiert noch, ob die vorgestellte Architektur auch von Oracle supportet wird bzw. wo die Grenzen liegen.
Ich könnte bspw. mir vorstellen, dass Oracle für das selbst definierte Action-Skript vermutlich keinen Support leisten wird.
Allerdings wäre eine generelle Aussage hinsichtlich Support für die Kombination von Single-Instance und Oracle Clusterware hilfreich.
Weiterhin existiert nun bereits die Clusterware in der Version 18. Gibt es hier eventuell Neuerungen hinsichtlich Unterstützung
eines Cold Failover Clusters für die Oracle Datenbank?
Unter Windows gibt es bekanntlich FailSafe. In unserer Umgebung ist Linux geplant, daher wäre eine „eingebaute“
Failover-Cluster-Unterstützung für die Oracle Datenbank in der Oracle Clusterware sehr vorteilhaft.
MfG,
Stefan
Hallo Stefan,
wie angekündigt, habe ich einen neuen Beitrag veröffentlicht, der den Aufbau eines Single Instance Failover Cluster in der aktuellen Version der Grid Infratructure (19c) zu Thema hat.
Möglicherweise ist das Thema ja noch interessant für Dich.
https://frankgerasch.de/2019/05/oracle-se2-im-cluster-es-geht-auch-ohne-rac/
Viele Grüße
Frank Gerasch